AI development is still mostly described as a model story. A new model ships, benchmark scores improve, context windows expand, tool use gets better, and the discussion moves on to the next release. That story is real, but it no longer explains where a growing share of the engineering difficulty actually lives.
A better description of the current shift is this: as models become more capable, the surrounding execution structure becomes more decisive. The next layer of competition is not just model intelligence. It is the harness around the model — the architecture that gives it context, tools, state, retries, guardrails, and observability.
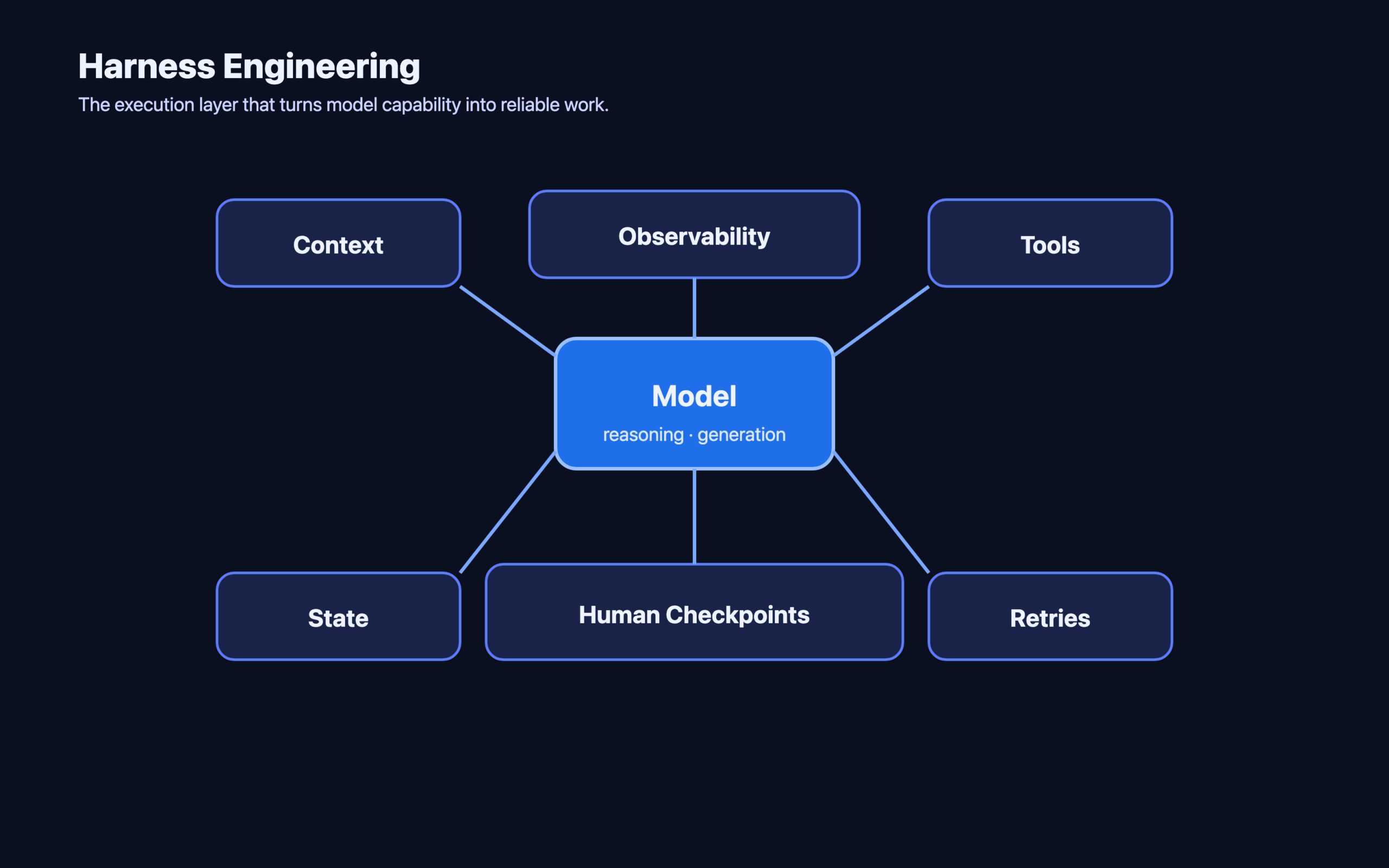
Harness engineering is what turns AI capability into reliable work.
Why this matters now
This shift matters now for at least four reasons:
- stronger base models are becoming easier to access
- coding agents are making system weaknesses visible in public
- long-running, tool-using workflows are becoming more common
- open repositories increasingly expose architecture, runtime structure, and evaluation logic rather than prompts alone
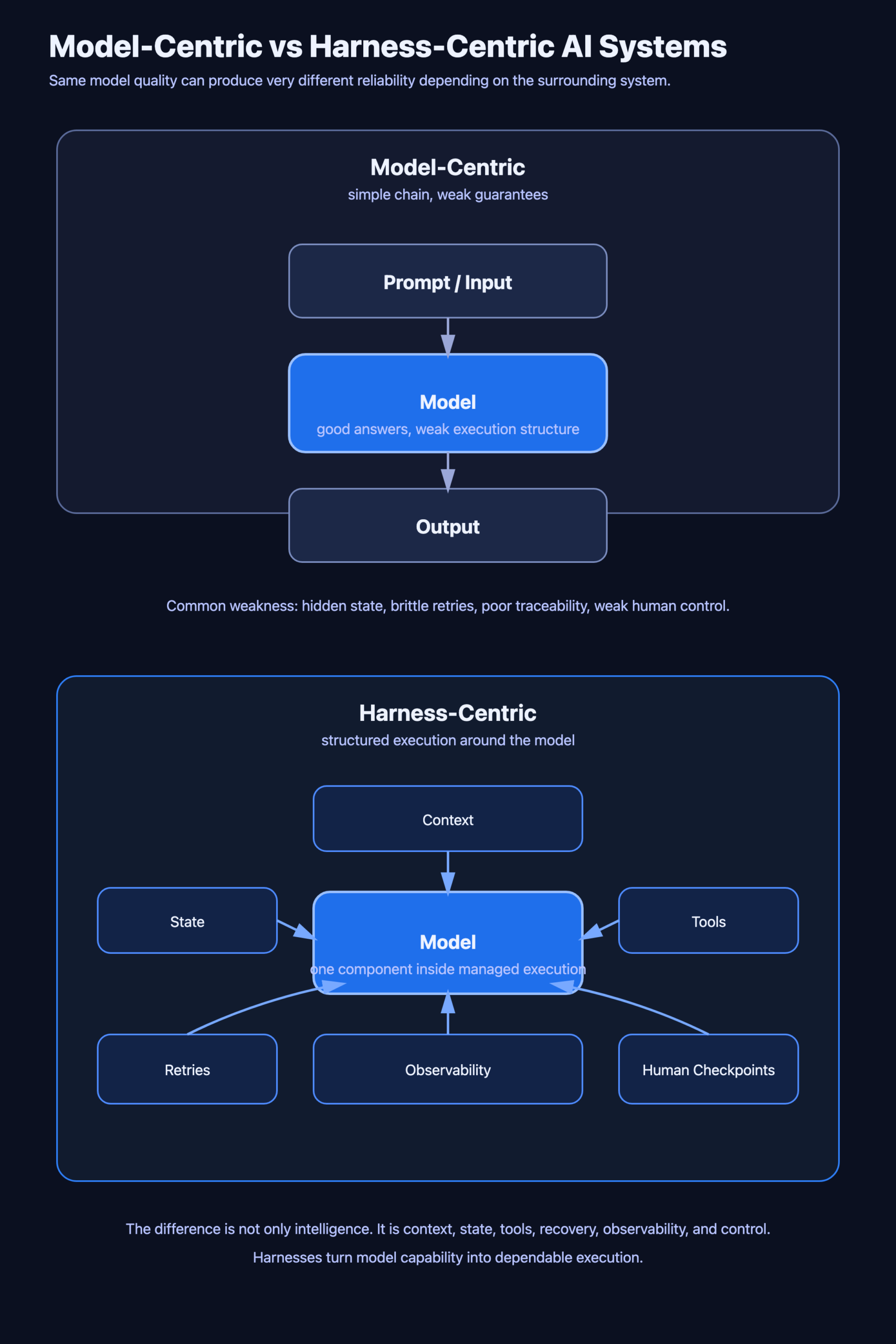
That changes what builders should pay attention to. It is no longer enough to ask whether a model is smart. The more useful question is whether the surrounding system can make that intelligence dependable.
Better models did not remove system design problems
Stronger models solve some problems, but they do not solve the system around the model.
A more capable model still needs the right context. It still needs boundaries around tool use. It still needs to survive long tasks, partial failures, interrupted execution, and ambiguous states. It still needs a way to explain what happened when things go wrong.
This distinction between model capability and system reliability is becoming one of the most important distinctions in practical AI engineering.
The recent paper Building AI Coding Agents for the Terminal: Scaffolding, Harness, Context Engineering, and Lessons Learned makes this explicit. It does not frame the problem as “pick a stronger model and let it run.” It frames the system in terms of shell execution, semantic code analysis, tool design, task management, and explicit completion signals.
Source URL: https://arxiv.org/html/2603.05344v1
That framing reflects a broader truth: once an AI system is expected to do real work across files, tools, shell commands, and user checkpoints, the engineering challenge becomes much bigger than prompt quality.
A strong model without a good harness is often just an expensive demo.
What harness engineering actually means
In plain English, harness engineering is the work of building the execution layer around a model so that the model can do useful work in a controlled, repeatable, and debuggable way.
A good harness usually defines some combination of:
- context management
- tool interfaces
- workflow state
- retries and recovery logic
- evaluation hooks
- traces and logs
- guardrails and constraints
- human approval or handoff points
A model call by itself can produce an impressive answer. A harness determines whether that answer becomes part of a usable system.
This is why the term matters. It shifts attention from isolated outputs to execution structure. A harness is what decides how a system receives context, how it takes action, how it records progress, how it recovers from failure, and how humans can inspect or intervene when needed.
Why coding agents exposed this so quickly
Coding agents are one of the clearest places to see this shift because they expose the limits of model-centric thinking almost immediately.
A model answering a single question can hide a lot of weaknesses. A model working inside a real codebase cannot. It has to navigate files, symbols, dependencies, shell commands, repository state, and multi-step tasks. It has to distinguish between partial progress and real completion. It has to avoid losing context in the middle of a long task.
That is why codebase context systems are becoming more important. GitNexus is a useful example because it treats repository understanding as a knowledge graph problem, not just a token problem.
Source URL: https://github.com/abhigyanpatwari/GitNexus
CodeGraphContext moves in a similar direction by indexing local code into a graph database and exposing that structure through both an MCP server and a CLI toolkit.
Source URL: https://github.com/CodeGraphContext/CodeGraphContext
The point is not that one tool will win. The point is that public implementations are converging on the same lesson: for serious coding workflows, bigger models are helpful, but structured repository context is becoming essential.
Public source code is revealing the same pattern
Once you look across public systems, the same architecture keeps reappearing.
LangGraph presents agent behavior as a graph with explicit state transitions and workflow structure.
Source URL: https://github.com/langchain-ai/langgraph
Restate’s AI examples emphasize durable execution, retries, persistence, and resilience.
Source URL: https://github.com/restatedev/ai-examples
Dapr Agents emphasizes workflow orchestration, state, telemetry, messaging, and security.
Source URL: https://github.com/dapr/dapr-agents
The OpenTelemetry MCP server shows observability moving closer to the agent layer itself, making traces part of the accessible tool environment rather than a separate human-only dashboard.
Source URL: https://github.com/traceloop/opentelemetry-mcp-server
Seen together, these are not random implementation details. They point to a shared pattern.
The pattern looks like this
- explicit state instead of hidden flow
- structured context instead of raw token stuffing
- tool boundaries instead of ad hoc tool calls
- retries and durability instead of brittle one-shot execution
- observability instead of opaque behavior
- human checkpoints instead of assumed autonomy
One of the clearest public signs of this shift is how reference hubs now organize the field. The awesome-harness-engineering repository, for example, groups the space into foundations, context and memory, guardrails, workflow design, evals, observability, and runtimes.
Source URL: https://github.com/walkinglabs/awesome-harness-engineering
That categorization matters because it reflects what builders are actually spending time on.
The competitive layer is moving outward
This does not mean model quality stopped mattering. It means model quality is no longer sufficient by itself.
As strong base models become easier to access, more of the practical difference moves into the surrounding system. Which team can represent context better? Which team can recover from failure gracefully? Which team can inspect a bad run and explain what happened? Which team can make long-running work repeatable instead of fragile?
Those are harness questions.
And that is why open source examples matter so much right now. They do not just show that teams are building agents. They show what kinds of system design are starting to become necessary when those agents are expected to do real work.
What builders should pay attention to now
If you are building with AI, it is still worth paying attention to models. But that is no longer where the whole game is.
A better set of questions is:
- how does the system receive and update context?
- how does it represent workflow state?
- how does it call tools and recover from tool failure?
- how does it trace what happened?
- how does it let humans inspect, intervene, or approve?
- how does it turn real-world failures into better evaluations?
These questions sound less glamorous than model launch headlines. But they are increasingly what separate an impressive demo from a dependable system.
Bottom line
The main shift in AI engineering is not that models stopped improving. It is that better models are making the surrounding architecture impossible to ignore.
That is why harness engineering is becoming a core skill. It is the discipline of making AI systems usable, reliable, inspectable, and repeatable under real conditions.
In the next part of this series, I will focus on one of the clearest pressure points behind this shift: why modern coding agents increasingly need structured codebase context rather than just larger models and longer context windows.
Sources
- walkinglabs/awesome-harness-engineering
- Building AI Coding Agents for the Terminal: Scaffolding, Harness, Context Engineering, and Lessons Learned
- langchain-ai/langgraph
- restatedev/ai-examples
- dapr/dapr-agents
- abhigyanpatwari/GitNexus
- CodeGraphContext/CodeGraphContext
- traceloop/opentelemetry-mcp-server
Leave a Reply