AI coding agents often look impressive in controlled demos and short benchmark tasks. They can explain code, generate functions, and suggest patches quickly. But once they are dropped into a real repository, their weaknesses become more obvious.
The problem is not only model quality. A stronger model can help, but it does not automatically create repository understanding. In practical software work, the bottleneck is increasingly whether the system can represent and retrieve codebase context in a form the model can use reliably over time.
That is why structured codebase context is becoming a core harness layer for serious coding agents.
Coding work exposes context failure faster than chat work
A normal chat task can hide a lot of weaknesses. A coding task cannot.
Real coding work depends on relationships between files, symbols, dependencies, tests, shell commands, partial edits, and repository state. The system has to track what changed, what still depends on that change, and what should be inspected next. It has to move between local detail and repository-wide structure without losing the thread.
That is very different from producing a one-shot answer. The challenge is not only generating plausible text. It is navigating a structured environment while preserving task continuity.
This is one reason the recent paper Building AI Coding Agents for the Terminal: Scaffolding, Harness, Context Engineering, and Lessons Learned is useful. It treats context engineering as a first-class systems problem, not just a prompt formatting detail.
Source URL: https://arxiv.org/html/2603.05344v1
That framing matters because coding agents fail in ways that expose the limits of raw model-centric thinking. They do not only hallucinate. They also lose track of repository structure, miss important references, forget prior steps, and confuse local correctness with system-level correctness.
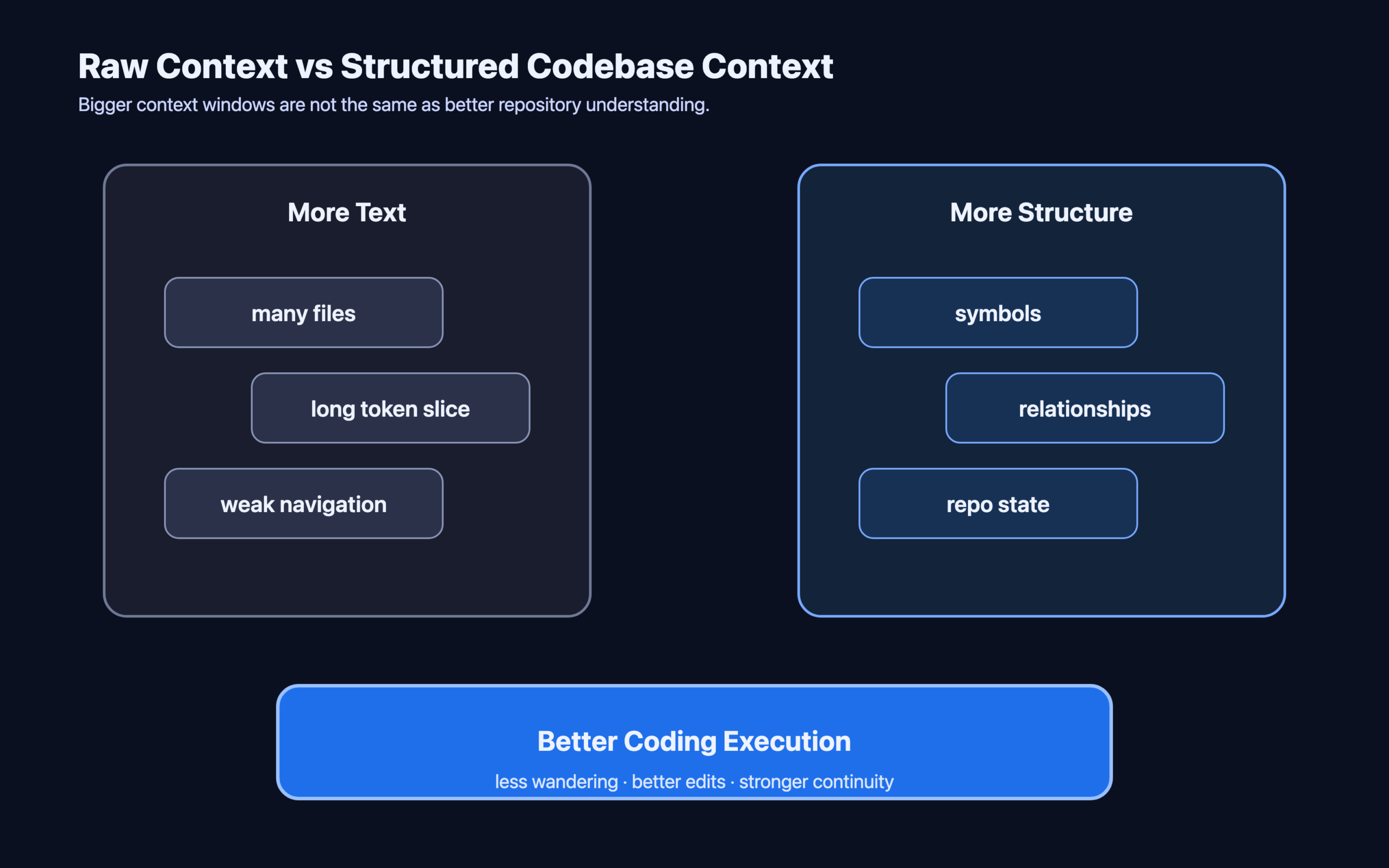
Bigger context windows are not the same as better context
One common response is to assume that larger context windows will solve the problem. They help, but they do not solve it.
More tokens are not the same as better repository understanding. A coding agent can be given more files and still fail to identify which symbols actually matter. It can see more text and still miss the most important relationships. It can load a larger slice of the repository and still struggle to maintain salience as the task evolves.
In other words, token volume is not a substitute for structure.
This is the central distinction: a codebase is not just a long string. It is an organized system of references, modules, call paths, dependencies, ownership boundaries, and changing states. Treating it as raw text may be enough for a demo. It is often not enough for real work.
What structured codebase context actually means
Structured codebase context means representing a repository in a way that makes its internal relationships usable.
That usually includes some combination of:
- symbol-level indexing
- file and module relationships
- reference and dependency tracking
- graph-like navigation between components
- retrieval tied to structure rather than only keyword similarity
- explicit links between local context and repository-wide context
The point is not to build an abstract graph because graphs sound sophisticated. The point is to reduce navigation failure.
A good coding harness needs a way to answer questions like:
- where is this symbol defined?
- what calls it?
- what else will break if this changes?
- what files are structurally adjacent to this task?
- what part of the repository matters right now?
Those are context questions, but they are also execution questions. They shape whether the agent can make progress without wandering.
Public systems are already moving in this direction
The clearest evidence here comes from public implementations.
GitNexus is a useful example because it approaches repository understanding as a structural problem rather than a pure prompt problem.
Source URL: https://github.com/abhigyanpatwari/GitNexus
That matters because it reflects a broader shift: repository context is increasingly being modeled, indexed, and navigated rather than simply pasted into prompts.
CodeGraphContext pushes in a similar direction. It indexes code into a graph-oriented layer and exposes it through both an MCP server and CLI tools.
Source URL: https://github.com/CodeGraphContext/CodeGraphContext
Again, the point is not that one implementation is the winner. The point is that public source code keeps converging on the same idea: coding agents need access to repository structure, not just larger piles of repository text.
This is also why Part 1 of this series argued that harness engineering is becoming more decisive. Once an agent must work across real files and long task chains, context handling becomes infrastructure.
Why this is a harness problem, not only a model problem
It is tempting to describe context handling as a retrieval trick attached to a model. That understates the issue.
For serious coding workflows, repository context is part of the harness itself. It determines how the system sees the codebase, how it updates its understanding over time, how it narrows attention, and how it keeps multi-step work coherent.
A stronger model may reason better once the right context is in place. But choosing a stronger model does not by itself decide:
- how repository structure is represented
- how relevant context is selected
- how changing state is tracked
- how prior work is remembered
- how partial progress is preserved across steps
Those are harness design choices.
And this is where a lot of real-world agent quality will likely be decided. As model capability becomes more accessible, the competitive edge moves toward systems that can make repository context usable, stable, and navigable.
Bottom line
The next bottleneck in AI coding is not just model intelligence. It is codebase context structure.
That is why structured codebase context is moving from a nice-to-have enhancement to a necessary layer in modern coding agents. For real software work, the question is no longer just whether the model can write code. It is whether the surrounding system can help the model understand where that code lives, what it affects, and what should happen next.
In the next part of this series, I will move from repository understanding to another pressure point in harness design: how long-running agent systems handle state, retries, interruptions, and durable execution.
Leave a Reply